Today we will look at an example of parsing posts from social systems in which a keyword is mentioned. For this we will use the service www.social-searcher.com.
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
#from fake_useragent import UserAgent
import os
import platform
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import time
from selenium.webdriver.common.proxy import Proxy, ProxyType
plt = platform.system()
driver_path = None
browser_path = None
if plt == "Windows":
#http://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Win_x64/902856/
driver_path = '../bin/windows/chromedriver_win32/chromedriver.exe'
browser_path = '../bin/windows/chrome-win/chrome.exe'
print(f"Your OS {plt}")
elif plt == "Linux":
#http://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Linux_x64/902856/
driver_path = '../bin/linux/chromedriver_linux64/chromedriver'
browser_path = '../bin/linux/chrome-linux/chrome'
print(f"Your OS {plt}")
elif plt == "Darwin":
#http://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Mac/902856/
driver_path = '../bin/linux/chromedriver_mac64/chromedriver'
browser_path = '../bin/linux/chrome-mac/chrome'
print(f"Your OS {plt}")
else:
print(f"Unidentified {plt}")
options = webdriver.ChromeOptions()
#
#ua = UserAgent()
#userAgent = ua.random
#options.add_argument(f'user-agent={userAgent}')
#
#options.add_argument('--user-agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0"')
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--disable-extensions')
options.add_argument('--test-type')
#options.add_argument('--single-process')
options.add_argument('--disable-gpu')
options.add_argument('--disable-software-rasterizer')
options.add_experimental_option("excludeSwitches", ["enable-logging"])
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.binary_location = browser_path
browser = webdriver.Chrome(executable_path = driver_path, options=options)
#browser.execute_cdp_cmd('Network.setUserAgentOverride', {"userAgent":"Mozilla/5.0 (Linux; Android 8.1.0; Pixel Build/OPM4.171019.021.D1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.109 Mobile Safari/537.36 EdgA/42.0.0.2057", "platform":"Windows"})
#browser.execute_cdp_cmd('Network.setUserAgentOverride', {"userAgent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.517 Safari/537.36", "platform":"Windows"})
browser.set_window_size(1920, 1080)
#browser.set_window_size(1024, 1024)
browser.maximize_window()
baseurls = ["https://www.social-searcher.com"]
methods = ['social-buzz', 'google-social-search']
sites = ['fb', 'tw', 'in']
keyword = "העבודה"
page_to = 10
params = '?q=' + keyword + ''.join(['&' + str(p) + '=on' for p in sites])
url = f'{baseurls[0]}/{methods[1]}/' + params
print(url)
browser.get(url)
time.sleep(2)
browser.save_screenshot("./screenshot.png")
posts = []
def parse_list(browser, social_name, page_num = 1):
print(f"Parsing {social_name} page #{page_num}")
html = browser.page_source
bs = BeautifulSoup(html, 'lxml')
cards_html = bs.find('div', {'class': 'gsc-expansionArea'})
cards_array = cards_html.find_all('div', {'class': 'gsc-webResult'})
for card in cards_array:
title = card.find('a', {'class': 'gs-title'}).text
text = card.find('div', {'class': 'gs-snippet'}).text
url = card.find('div', {'class': 'gs-visibleUrl-long'}).text
pic=None
try:
pic = card.find('img', {'class': 'gs-image'})['src']
except:
#print("-")
pass
post = {title: title, text: text, url: url, pic: pic}
posts.append(post)
time.sleep(3)
browser.save_screenshot("./screenshot.png")
iframes = browser.find_elements_by_class_name('iframe-column')
for social in browser.find_elements_by_class_name('iframe-column'):
social_name = social.find_element_by_class_name('network-name').text
social_iframe = social.find_element_by_tag_name('iframe')
browser.switch_to.frame(social_iframe)
#
parse_list(browser, social_name, page_num = 1)
for page_num in range(2, page_to + 1, 1):
page_link = browser.find_element_by_xpath(f"//div[@aria-label='Page {page_num}']")
browser.execute_script("arguments[0].click();", page_link)
parse_list(browser, social_name, page_num)
#
browser.switch_to.default_content()
print(posts)
browser.quit()The service offers paid and shareware usage rates. We need a free one. The relevant links are:
- https://www.social-searcher.com/google-social-search -free
- https://www.social-searcher.com/social-buzz — shareare with limit 100 request
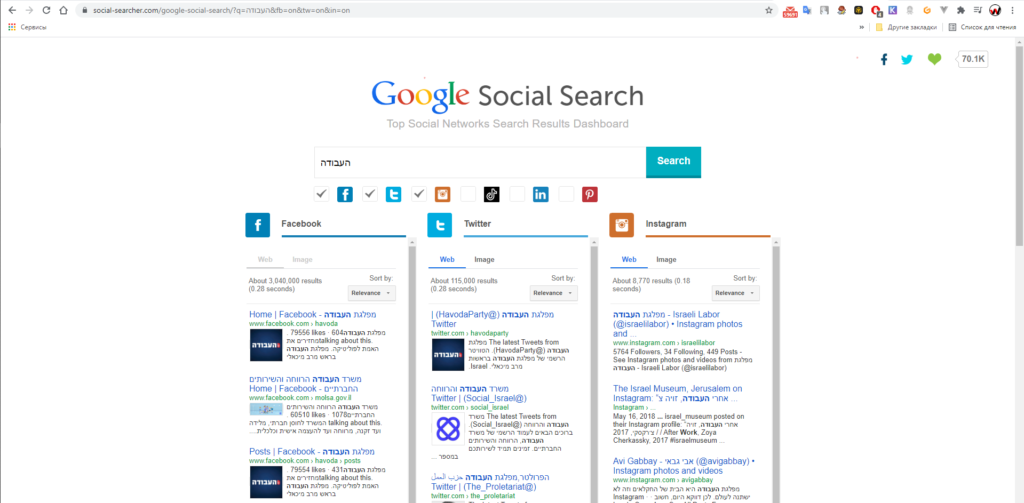
What does the script do? The script opens a page by a link, inserts a keyword, ticks the boxes to search for the desired social networks and makes parsing page by page in turn
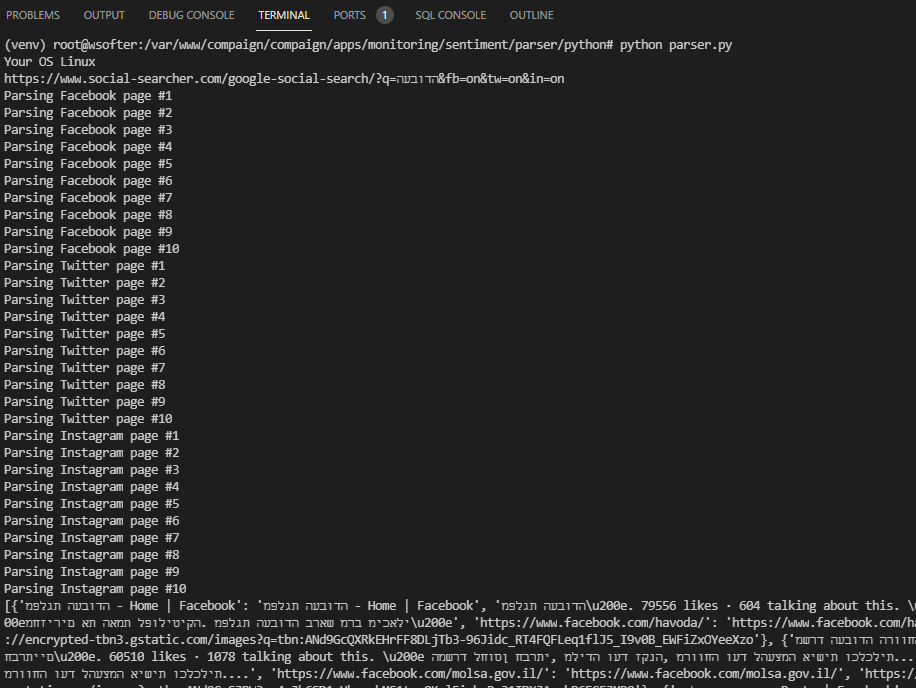
Below is an advanced parsing code with autoiteration of keywords
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
#from fake_useragent import UserAgent
import datetime
import os
import platform
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import time
from selenium.webdriver.common.proxy import Proxy, ProxyType
plt = platform.system()
driver_path = None
browser_path = None
if plt == "Windows":
#You must download here http://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Win_x64/902856/
driver_path = '../bin/windows/chromedriver_win32/chromedriver.exe'
browser_path = '../bin/windows/chrome-win/chrome.exe'
print(f"Your OS {plt}")
elif plt == "Linux":
#You must download here http://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Linux_x64/902856/
driver_path = '../bin/linux/chromedriver_linux64/chromedriver'
browser_path = '../bin/linux/chrome-linux/chrome'
print(f"Your OS {plt}")
elif plt == "Darwin":
#You must download here http://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Mac/902856/
driver_path = '../bin/linux/chromedriver_mac64/chromedriver'
browser_path = '../bin/linux/chrome-mac/chrome'
print(f"Your OS {plt}")
else:
print(f"Unidentified {plt}")
options = webdriver.ChromeOptions()
#
#ua = UserAgent()
#userAgent = ua.random
#options.add_argument(f'user-agent={userAgent}')
#
#options.add_argument('--user-agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0"')
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--disable-extensions')
options.add_argument('--test-type')
#options.add_argument('--single-process')
options.add_argument('--disable-gpu')
options.add_argument('--disable-software-rasterizer')
options.add_experimental_option("excludeSwitches", ["enable-logging"])
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.binary_location = browser_path
browser = webdriver.Chrome(executable_path = driver_path, options=options)
#browser.execute_cdp_cmd('Network.setUserAgentOverride', {"userAgent":"Mozilla/5.0 (Linux; Android 8.1.0; Pixel Build/OPM4.171019.021.D1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.109 Mobile Safari/537.36 EdgA/42.0.0.2057", "platform":"Windows"})
#browser.execute_cdp_cmd('Network.setUserAgentOverride', {"userAgent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.517 Safari/537.36", "platform":"Windows"})
browser.set_window_size(1920, 1080)
browser.maximize_window()
parsing_date = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
baseurls = ["https://www.social-searcher.com"] #Service for parsing
methods = ['google-social-search', 'social-buzz'] #Subservices/plans for parsing
sites = ['fb', 'tw', 'in'] #Social networks for parsing
keywords = ["מפלגת העבודה", "שרת התחבורה", "מיכאלי", "מירב מיכאלי"] #Keywords
page_to = 10 #Total pages for parsing(max=10)
posts = [] #List for saving parsed posts
def parse_list(browser, social_name, keyword, page_num = 1):
#Print current page info
print(f"Parsing {social_name} with keyword @{keyword} on page #{page_num}")
html = browser.page_source
bs = BeautifulSoup(html, 'lxml')
cards_html = bs.find('div', {'class': 'gsc-expansionArea'})
cards_array = cards_html.find_all('div', {'class': 'gsc-webResult'})
#Iterate by post list on current page
for card in cards_array:
name = card.find('a', {'class': 'gs-title'}).text
text = card.find('div', {'class': 'gs-snippet'}).text
url = card.find('div', {'class': 'gs-visibleUrl-long'}).text
date = None
pic=None
try:
pic = card.find('img', {'class': 'gs-image'})['src']
except:
pass
#Creating post info set
post = {
'date_of_add': parsing_date,
'post': url,
'pic': pic,
'name': name,
'date': date,
'text': text,
'keyword': keyword,
'sentiment': None,
'social_name': social_name
}
posts.append(post)
time.sleep(3)
browser.save_screenshot("./screenshot.png")
#Iterating by keyords
for keyword in keywords:
#Generate URL for parsing with keyword and social params
params = '?q=' + keyword + ''.join(['&' + str(p) + '=on' for p in sites])
url = f'{baseurls[0]}/{methods[0]}/' + params
print(url)
#Locate by generated URL
browser.get(url)
time.sleep(2)
browser.save_screenshot("./screenshot.png")
#Iterate by social data by him iframe columns
for social in browser.find_elements_by_class_name('iframe-column'):
social_name = social.find_element_by_class_name('network-name').text
social_iframe = social.find_element_by_tag_name('iframe')
browser.switch_to.frame(social_iframe)
#Parsing the first page
parse_list(browser, social_name, keyword, page_num = 1)
#Parsing other pages
for page_num in range(2, page_to + 1, 1):
page_link = browser.find_element_by_xpath(f"//div[@aria-label='Page {page_num}']")
browser.execute_script("arguments[0].click();", page_link)
parse_list(browser, social_name, keyword, page_num)
#Switch browser content from iframe to main frame
browser.switch_to.default_content()
print(posts)
browser.quit()

